Claas A. Voelcker
PostDoc at the University of Texas at Austin, RL researcher focused on too many things, he/him, 🏳️🌈 🤖 🧙

GDC 4.306
2317 SPEEDWAY
AUSTIN, TX 78712
I am a PostDoc focused on Reinforcement and Machine Learning at the University of Texas at Austin, where I work with Peter Stone and Amy Zhang. Previously I received a PhD from the University of Toronto and the Vector Institute, where I was fortunate to be advised by Profs. Amir-massoud Farahmand and Igor Gilitschenski.
Originally from Germany, I received a Bachelor and Master degree from the University of Darmstadt with Honors. There, I had the great pleasure to be supervised and mentored by Profs. Kristian Kersting and Jan Peters.
I am proud to serve as a core organizer for Queer in AI, where I help promote the interests of queer researchers and practitioners at AI /ML conferences and in the wider community.
Research Vision
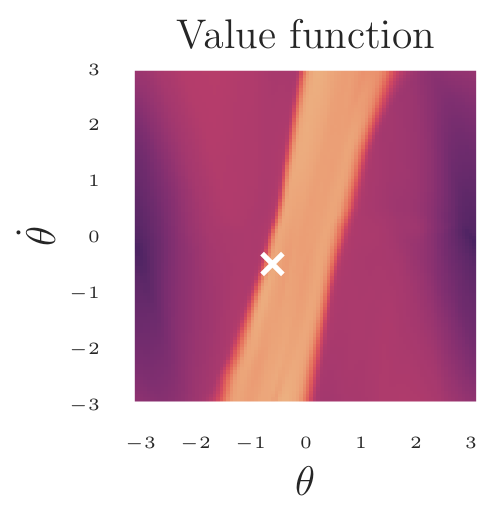
To make good decisions, intelligent agents need to evaluate the consequences and quality of their actions. In Reinforcement Learning, this quality is captured by the value function. My driving research question is how we enable autonomous AI to learn good value functions and to accurately estimate the impact of their actions. To achieve this, I have worked on a variety of techniques that make value learning fast, efficient, and accurate.
Works that train and leverage value functions
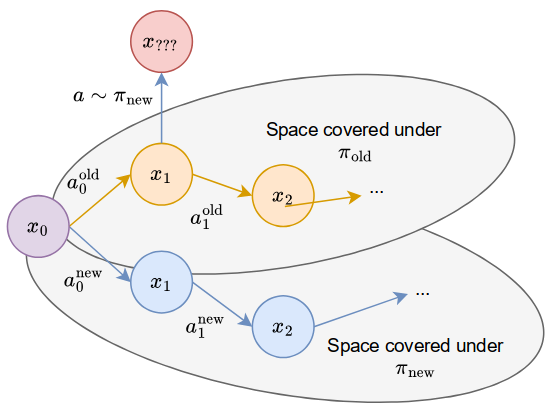
- In Update-free Steering we show how value functions can be used to improve pre-trained robotics policies at execution time.
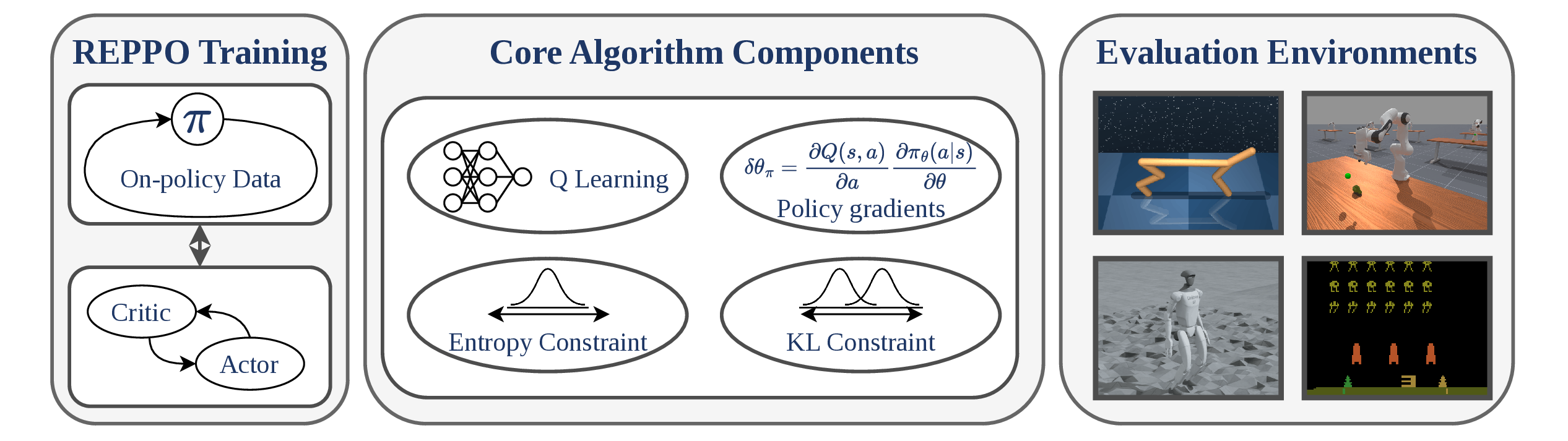
- In REPPO we present an algorithm that is able to leverage strong action value function learning for lightning fast on-policy improvements in hard robotics tasks.
- In MAD-TD we look at how simulated data from a learned world model can improve an agent’s value estimation.
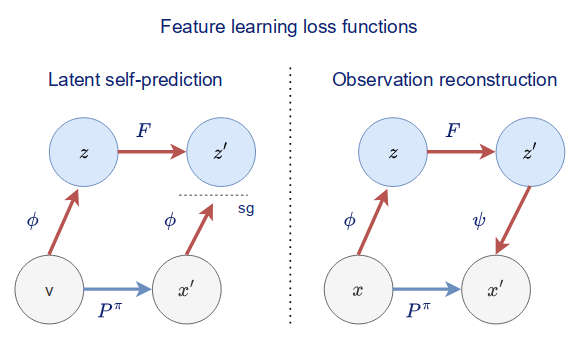
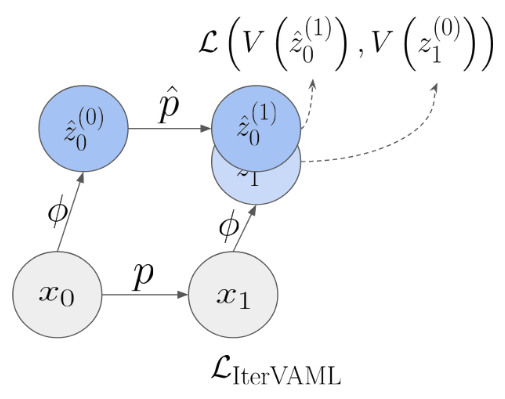
- In When does self-prediction help we take a look at different auxiliary tasks and explain how they help stabilize value learning.
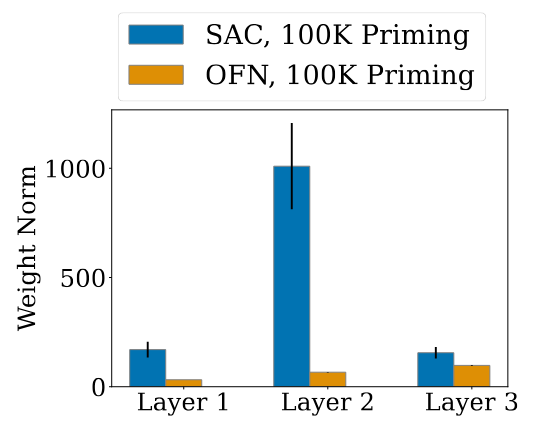
- In Dissecting Deep RL we investigate architectural regularizations that prevent agents from overestimating the value of their actions,
news
| Mar 12, 2026 | New papers! We pre-published “Update-Free On-Policy Steering via Verifiers”, a method that uses on-policy value functions to steer pre-trained robotics policies in real! We are also very grateful that “Relative ENtropy Pathwise Policy Optimization” was accepted to ICLR 2026. See you in Rio! |
|---|---|
| Feb 12, 2026 | I gave a talk on REPPO at the BeNeRL Seminar. You can find my slides here. |
| Nov 04, 2025 | I finally started my postdoc position at the University of Texas at Austin! So excited for the coming years filled with RL and robotics discoveries. |
| Oct 02, 2025 | Our new paper Relative Entropy Pathwise Policy Optimization has a blog post that goes through everything you need to know to about implementing it yourself and understanding the technical bits and pieces. |
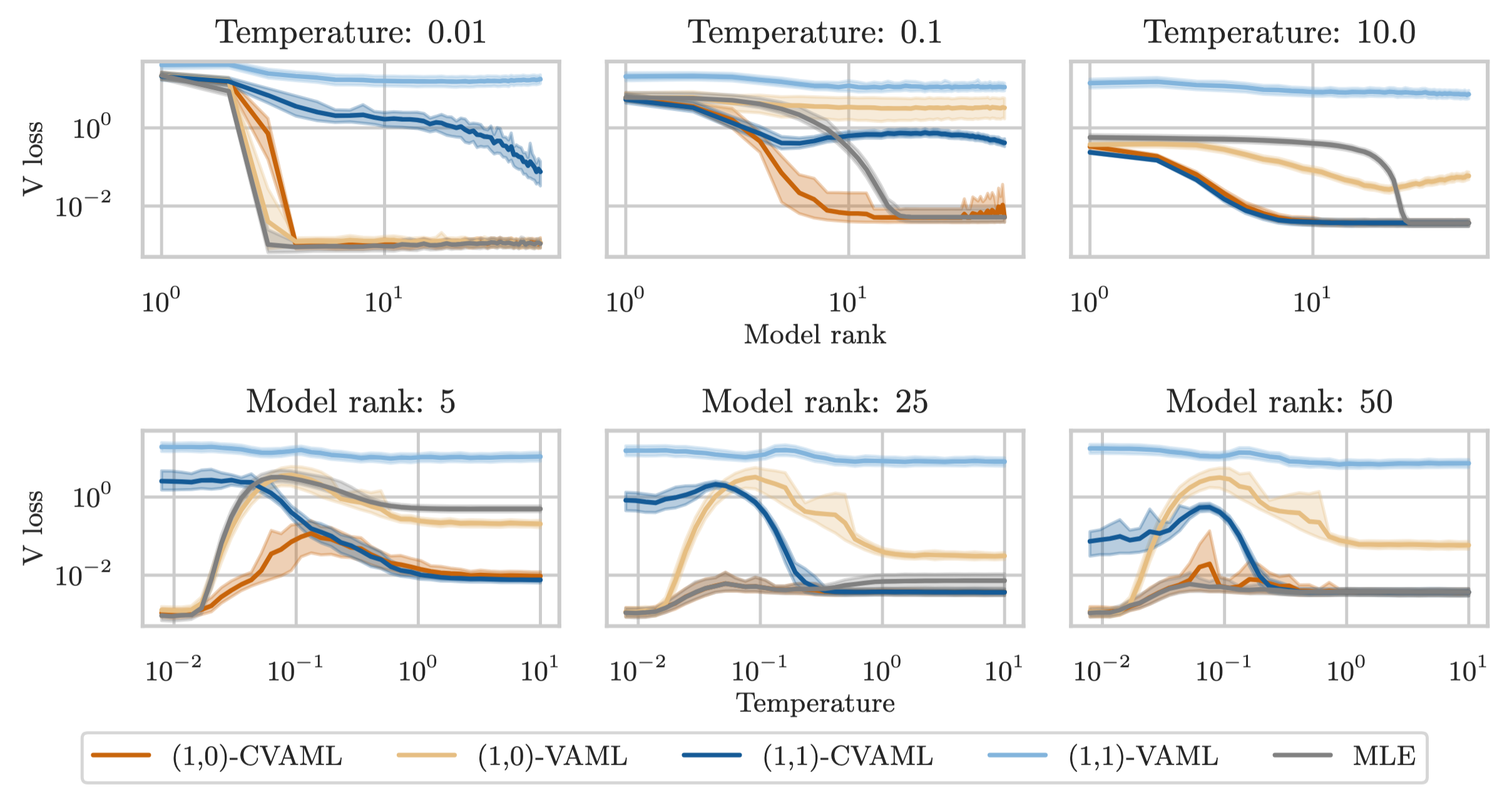
| Jul 01, 2025 | Our paper Calibrated Value-Aware Model Learning with Probabilistic Environment Models will be presented at ICML 2025 in Vancouver next week! Let me know if you want to meet up for a coffee. |
latest posts
selected publications
2026
-
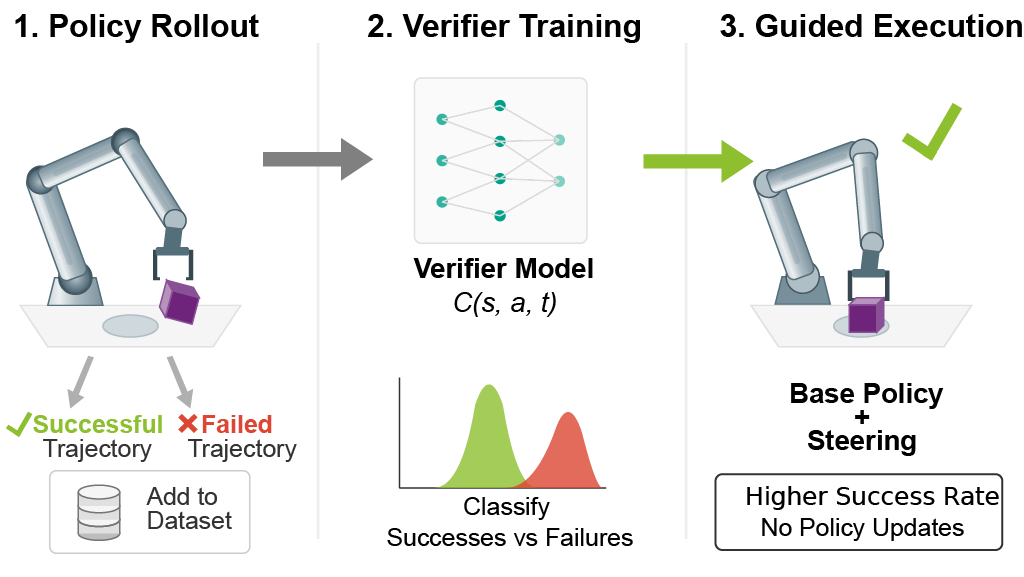 Update-Free On-Policy Steering via VerifiersMar 2026
Update-Free On-Policy Steering via VerifiersMar 2026